OPEN-SOURCE SCRIPT
Updated Lorentzian Key Support and Resistance Level Detector [mishy]
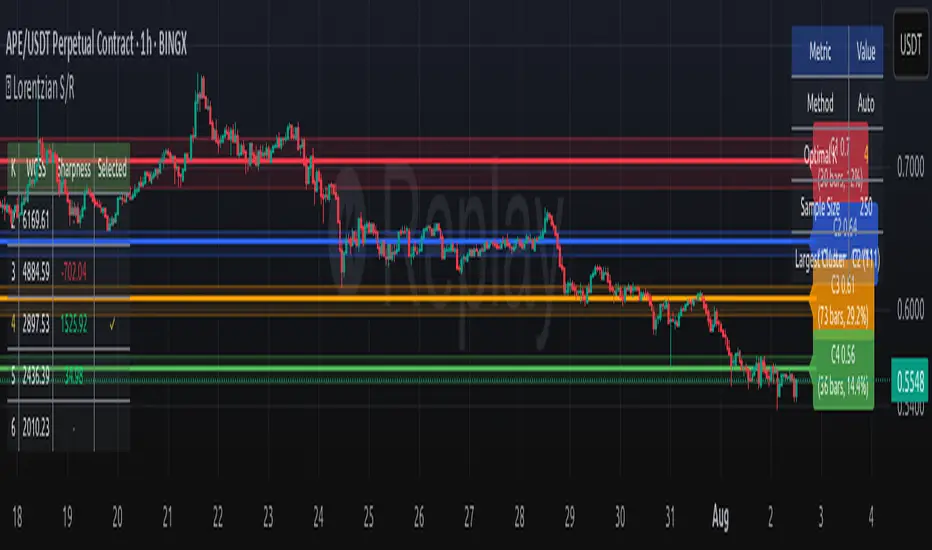
🧮 Lorentzian Key S/R Levels Detector
Advanced Support & Resistance Detection Using Mathematical Clustering
The Problem
Traditional S/R indicators fail because they're either subjective (manual lines), rigid (fixed pivots), or break when price spikes occur. Most importantly, they don't tell you where prices actually spend time, just where they touched briefly.
The Solution: Lorentzian Distance Clustering
This indicator introduces a novel approach by using Lorentzian distance instead of traditional Euclidean distance for clustering. This is groundbreaking for financial data analysis.
Data Points Clustering:
🔬 Why Euclidean Distance Fails in Trading
Traditional K-means uses Euclidean distance:
• Formula:Pine Script®
• Problem: Squaring amplifies differences exponentially
• Real impact: One 5% price spike has 25x more influence than a 1% move
• Result: Clusters get pulled toward outliers, missing real support/resistance zones
Example scenario:
Pine Script®
⚡ Lorentzian Distance: The Game Changer
Our approach uses Lorentzian distance:
• Formula:Pine Script®
• Breakthrough: Logarithmic compression keeps outliers in check
• Real impact: Large moves still matter, but don't dominate
• Result: Clusters focus on where prices actually spend time
Same example with Lorentzian:
Pine Script®
🧠 Adaptive Intelligence
The σ parameter isn't fixed,it's calculated from market disturbance/entropy:
• High volatility: σ increases, making algorithm more tolerant of large moves
• Low volatility: σ decreases, making algorithm more sensitive to small changes
• Self-calibrating: Adapts to any instrument or market condition automatically
Why this matters: Traditional methods treat a 2% move the same whether it's in a calm or volatile market. Lorentzian adapts the sensitivity based on current market behavior.
🎯 Automatic K-Selection (Elbow Method)
Instead of guessing how many S/R levels to draw, the indicator:
• Tests 2-6 clusters and calculates WCSS (tightness measure)
• Finds the "elbow" - where adding more clusters stops helping much
• Uses sharpness calculation to pick the optimal number automatically
Result: Perfect balance between detail and clarity.
How It Works
1. Collect recent closing prices
2. Calculate entropy to adapt to current market volatility
3. Cluster prices using Lorentzian K-means algorithm
4. Auto-select optimal cluster count via statistical analysis
5. Draw levels at cluster centers with deviation bands
📊 Manual K-Selection Guide (Using WCSS & Sharpness Analysis)
When you disable auto-selection, use both WCSS and Sharpness metrics from the analysis table to choose manually:
What WCSS tells you:
• Lower WCSS = tighter clusters = better S/R levels
• Higher WCSS = scattered clusters = weaker levels
What Sharpness tells you:
• Higher positive values = optimal elbow point = best K choice
• Lower/negative values = poor elbow definition = avoid this K
• Measures the "sharpness" of the WCSS curve drop-off
Decision strategy using both metrics:
Pine Script®
Quick decision rules:
• Pick K with highest positive Sharpness (indicates optimal elbow)
• Confirm with significant WCSS drop (30%+ reduction is good)
• Avoid K values with negative or very low Sharpness (<1.0)
• K=3 above shows: Big WCSS drop (41%) + High Sharpness (22.04) = Perfect choice
Why this works:
The algorithm finds the "elbow" where adding more clusters stops being useful. High Sharpness pinpoints this elbow mathematically, while WCSS confirms the clustering quality.
Elbow Method Visualization:
Traditional clustering problems:
❌ Price spikes distort results
❌ Fixed parameters don't adapt
❌ Manual tuning is subjective
❌ No way to validate choices
Lorentzian solution:
☑️ Outlier-resistant distance metric
☑️ Entropy-based adaptation to volatility
☑️ Automatic optimal K selection
☑️ Statistical validation via WCSS & Sharpness
Features
Visual:
• Color-coded levels (red=highest resistance, green=lowest support)
• Optional deviation bands showing cluster spread
• Strength scores on labels: Each cluster shows a reliability score.
• Higher scores (0.8+) = very strong S/R levels with tight price clustering
• Lower scores (0.6-0.7) = weaker levels, use with caution
• Based on cluster tightness and data point density
• Clean line extensions and labels
Analytics:
• WCSS analysis table showing why K was chosen
• Cluster metrics and statistics
• Real-time entropy monitoring
Control:
• Auto/manual K selection toggle
• Customizable sample size (20-500 bars)
• Show/hide bands and metrics tables
The Result
You get mathematically validated S/R levels that focus on where prices actually cluster, not where they randomly spiked. The algorithm adapts to market conditions and removes guesswork from level selection.
Best for: Traders who want objective, data-driven S/R levels without manual chart analysis.
Credits: This script is for educational purposes and is inspired by the work of ThinkLogicAI and an amazing mentor DskyzInvestments . It demonstrates how Lorentzian geometrical concepts can be applied not only in ML classification but also quite elegantly in clustering.
Advanced Support & Resistance Detection Using Mathematical Clustering
The Problem
Traditional S/R indicators fail because they're either subjective (manual lines), rigid (fixed pivots), or break when price spikes occur. Most importantly, they don't tell you where prices actually spend time, just where they touched briefly.
The Solution: Lorentzian Distance Clustering
This indicator introduces a novel approach by using Lorentzian distance instead of traditional Euclidean distance for clustering. This is groundbreaking for financial data analysis.
Data Points Clustering:
🔬 Why Euclidean Distance Fails in Trading
Traditional K-means uses Euclidean distance:
• Formula:
distance = (price_A - price_B)²
• Problem: Squaring amplifies differences exponentially
• Real impact: One 5% price spike has 25x more influence than a 1% move
• Result: Clusters get pulled toward outliers, missing real support/resistance zones
Example scenario:
Prices: [100, 101, 102, 98, 99, 150] ← flash spike
Euclidean: Centroid gets dragged toward 150
Actual S/R zone: Around 100 (where prices actually trade)
⚡ Lorentzian Distance: The Game Changer
Our approach uses Lorentzian distance:
• Formula:
distance = log(1 + (price_difference)² / σ²)
• Breakthrough: Logarithmic compression keeps outliers in check
• Real impact: Large moves still matter, but don't dominate
• Result: Clusters focus on where prices actually spend time
Same example with Lorentzian:
Prices: [100, 101, 102, 98, 99, 150] ← flash spike
Lorentzian: Centroid stays near 100 (real trading zone)
Outlier (150): Acknowledged but not dominant
🧠 Adaptive Intelligence
The σ parameter isn't fixed,it's calculated from market disturbance/entropy:
• High volatility: σ increases, making algorithm more tolerant of large moves
• Low volatility: σ decreases, making algorithm more sensitive to small changes
• Self-calibrating: Adapts to any instrument or market condition automatically
Why this matters: Traditional methods treat a 2% move the same whether it's in a calm or volatile market. Lorentzian adapts the sensitivity based on current market behavior.
🎯 Automatic K-Selection (Elbow Method)
Instead of guessing how many S/R levels to draw, the indicator:
• Tests 2-6 clusters and calculates WCSS (tightness measure)
• Finds the "elbow" - where adding more clusters stops helping much
• Uses sharpness calculation to pick the optimal number automatically
Result: Perfect balance between detail and clarity.
How It Works
1. Collect recent closing prices
2. Calculate entropy to adapt to current market volatility
3. Cluster prices using Lorentzian K-means algorithm
4. Auto-select optimal cluster count via statistical analysis
5. Draw levels at cluster centers with deviation bands
📊 Manual K-Selection Guide (Using WCSS & Sharpness Analysis)
When you disable auto-selection, use both WCSS and Sharpness metrics from the analysis table to choose manually:
What WCSS tells you:
• Lower WCSS = tighter clusters = better S/R levels
• Higher WCSS = scattered clusters = weaker levels
What Sharpness tells you:
• Higher positive values = optimal elbow point = best K choice
• Lower/negative values = poor elbow definition = avoid this K
• Measures the "sharpness" of the WCSS curve drop-off
Decision strategy using both metrics:
K=2: WCSS = 150.42 | Sharpness = - | Selected =
K=3: WCSS = 89.15 | Sharpness = 22.04 | Selected = ✓ ← Best choice
K=4: WCSS = 76.23 | Sharpness = 1.89 | Selected =
K=5: WCSS = 73.91 | Sharpness = 1.43 | Selected =
Quick decision rules:
• Pick K with highest positive Sharpness (indicates optimal elbow)
• Confirm with significant WCSS drop (30%+ reduction is good)
• Avoid K values with negative or very low Sharpness (<1.0)
• K=3 above shows: Big WCSS drop (41%) + High Sharpness (22.04) = Perfect choice
Why this works:
The algorithm finds the "elbow" where adding more clusters stops being useful. High Sharpness pinpoints this elbow mathematically, while WCSS confirms the clustering quality.
Elbow Method Visualization:
Traditional clustering problems:
❌ Price spikes distort results
❌ Fixed parameters don't adapt
❌ Manual tuning is subjective
❌ No way to validate choices
Lorentzian solution:
☑️ Outlier-resistant distance metric
☑️ Entropy-based adaptation to volatility
☑️ Automatic optimal K selection
☑️ Statistical validation via WCSS & Sharpness
Features
Visual:
• Color-coded levels (red=highest resistance, green=lowest support)
• Optional deviation bands showing cluster spread
• Strength scores on labels: Each cluster shows a reliability score.
• Higher scores (0.8+) = very strong S/R levels with tight price clustering
• Lower scores (0.6-0.7) = weaker levels, use with caution
• Based on cluster tightness and data point density
• Clean line extensions and labels
Analytics:
• WCSS analysis table showing why K was chosen
• Cluster metrics and statistics
• Real-time entropy monitoring
Control:
• Auto/manual K selection toggle
• Customizable sample size (20-500 bars)
• Show/hide bands and metrics tables
The Result
You get mathematically validated S/R levels that focus on where prices actually cluster, not where they randomly spiked. The algorithm adapts to market conditions and removes guesswork from level selection.
Best for: Traders who want objective, data-driven S/R levels without manual chart analysis.
Credits: This script is for educational purposes and is inspired by the work of ThinkLogicAI and an amazing mentor DskyzInvestments . It demonstrates how Lorentzian geometrical concepts can be applied not only in ML classification but also quite elegantly in clustering.
Release Notes
Label Fix: Bar Count & Density% Shown. Release Notes
Bug Fixed.Open-source script
In true TradingView spirit, the creator of this script has made it open-source, so that traders can review and verify its functionality. Kudos to the author! While you can use it for free, remember that republishing the code is subject to our House Rules.
Disclaimer
The information and publications are not meant to be, and do not constitute, financial, investment, trading, or other types of advice or recommendations supplied or endorsed by TradingView. Read more in the Terms of Use.
Open-source script
In true TradingView spirit, the creator of this script has made it open-source, so that traders can review and verify its functionality. Kudos to the author! While you can use it for free, remember that republishing the code is subject to our House Rules.
Disclaimer
The information and publications are not meant to be, and do not constitute, financial, investment, trading, or other types of advice or recommendations supplied or endorsed by TradingView. Read more in the Terms of Use.